
Introduction
The software XML-Print is used to typeset arbitrary XML files. The joint research project is funded by the German Research Foundation (DFG) for the period starting 1 March 2010 to 28 February 2014. It is a key component of the TextGridLab, which has been under continuous development since 2008.1
XML-Print supports users in formatting their semantically annotated data rulebased and in outputting a high-quality PDF document. Based on existing standards like XSL (XSLT and XSL-FO), Unicode and OpenType, a modern graphical user interface offers different kinds of layout options. Those are then processed by a newly developed typesetting engine using the functional programming language F#.
Scholarly Typesetting
XML-Print targets in particular specific challenges from the typesetting of scholarly texts such as critical editions, multilingual synoptic editions or scholarly dictionaries.
Taking the example of critical editions as a key product of philological research, they regular attempt to fully describing alternative existing witnesses of the text (old manuscripts, early prints, etc.) and fully covering the genesis of the text (authorial or scribal additions, deletions, comments, etc.).
Critical editions in print use specific layout conventions. The editor notes witnesses in one apparatus and often adds their explanations in a critical apparatus which constitutes a fourth flow on the page. More complex layouts can include more critical apparatus and/or annotations in margins. Other challenges beyond the ‘normal’ typesetting tasks include in particular synoptic prints, marginalia with complex references, unusual or non-standard characters and symbols, including those not (yet) present in the Unicode specifications etc.
State of the Art
Many humanities scholars have started to encode their work as XML files. The TEI guidelines have been a major contribution to that. However, when it comes to the stage of publication often problems arise: What tool should be used for that? There are of course well-known solutions: Open-source typesetting engines like TeX (Knuth, 1986) and TUSTEP (Ott, 1979) can be ‘programmed’ to convert large amounts of XML data somehow into their own markup language and then into an output format, typically PDF. However both batch systems need an experienced and skilled user in order to get high-quality results. Very often individual and highly specialized extensions have to be added, in particular in view of the challenges of non-standard typesetting requirements such as multiple apparatus. In addition these systems suffer from the problem of content mixed up with formatting information.
Apart from batch systems many proprietary ‘WYSIWYG’ software came up through the years, e.g. the Critical Edition Typesetter (CET) and the Classical Text Editor (CTE). These are, however, mostly isolated solutions with data – once input and annotated – ‘getting lost’ in a proprietary format.
From the commercial ‘desktop publishing’ sector Adobe InDesign is a reasonable choice using its own XML format as a medium step, but it lacks in the implementation of scientific printing. The same is valid for office suites which are not meant for high-quality typesetting of scientific content.
More about the requirements of scientific typesetting and existing solutions can be found in Küster and Ludwig (2008).
Functionality
The following use case is a typical example for the publication of an XML file using XML-Print: A scholar has a critical edition encoded in XML and wants to present a first printed version to their colleagues. In order to do so they have to perform the following steps:
- Identify different structures and think about corresponding ways of formatting, e.g. for chapters, sections, footnotes, paragraphs etc.
- Create a format for each of the identified structures. Set sizes, spaces, text decorations and other attributes as needed. Modify the standard format if necessary.
- Use the mapping dialog to select pairs of XML elements and formats.
- Start the integrated typesetting engine to get a PDF document.
- If necessary, make changes to the XML source and/or alter formats and mappings.
Figure 1 illustrates the overall data flow.
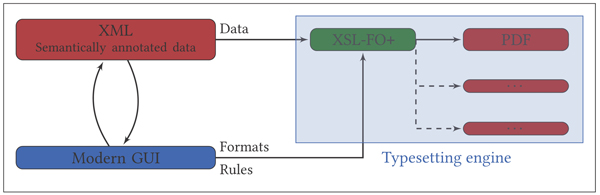
Figure 1: Data flow in XML-Print: The user decides on the formatting of an annotated XML text with the help of a GUI (front-end). Those information are then merged into a XSL-FO+ file and converted into an internal intermediate format for typesetting (back-end). At last the renderer outputs a PDF file (or any other supported format)
Graphical User Interface (GUI)
A user-friendly and modern GUI is essential for the acceptance by the ‘community’ (cf. Nielsen 1993; Warwick et al. 2011). To make integration into the toolbox of the TextGridLab easier, the front-end has been implemented as an Eclipse plug-in using the Rich Client Platform (RCP) technology. It offers ways to select different layout options which are then incorporated into a dynamic XSLT stylesheet to generate an XSL-FO+ file. This format is based on the standard XSL-FO, but continuously extended where needed.2
Figure 2 shows the user’s view on the XML-Print GUI.
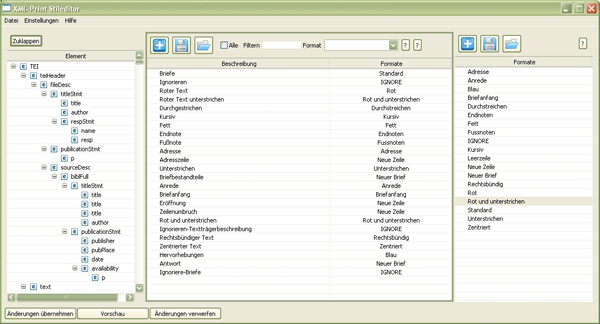
Figure 2: The user’s view on the GUI of XML-Print is tripartite: On the left the XML tree can be expanded while the formats are listed on the right. The middle part links those both together by mappings
Formats
Each format is a set of XSL-FO+ attributes. They determine the concrete rendering later on by the typesetting engine. The attributes are divided into categories inspired by the XSL-FO terminology (block, inline, footnote etc.) to easily navigate through. This idea was derived from similar software familiar to many users. This way the user can set all appropriate values as needed.
New formats can be created and existing ones may be copied, edited or deleted. The complete set of formats can then be saved and transferred to another scholar or can be used for any other XML-Print project.
Mappings
Each XML element can be mapped to a format. Different attribute values can be considered as well, e.g. to distinguish <note type=”footnoteA”> from <note type=”footnoteB”>. The selection of corresponding structures can be easily done directly on the XML tree. Alternatively an arbitrary XPath expression can be used.
Mappings can not only be created, edited and deleted, but also deactivated for testing purposes. A rank order is also established to allow the scholar to use overlapping mappings, i.e. XML structures belonging to more than one mapping.
Typesetting Engine
The disadvantages of existing approaches stated in section 3 led to the decision for a completely new typesetting engine. Established algorithms like the one by Knuth and Plass (1981) are combined with new ideas (cf. Brüggemann-Klein et al. 2003) and open-source libraries like Hunspell and iText are incorporated by a functional approach using the programming language F# as part of the .NET framework and its implementation both under Microsoft .NET and its open-source, cross-platform counterpart Mono.
Functional programming coexists with imperative programming for quite some time3, but was often considered to be too ‘academic’. This has, however, changed over the last years not least because of some important advantages arising from the different approach on modern multicore systems that are available everywhere: no side effects, better evaluation techniques and strong abilities for modularization and parallelism (see e.g. Hughes 1990).
Of course, all essential features of recent typesetting engines are to be implemented, i.e. good line and page breaking, support of OpenType fonts, floating objects, tables, lists etc. For the underlying access to OpenType fonts and PDF generation we leverage existing cross-platform, open-source libraries such as iTeXtSharp. The main focus, however, has been on those algorithms which substantially improve the quality compared to existing programs. Thus we have already implemented an interface to typeset an arbitrary number of footnotes and apparatus. Other important and requested features are multi-column layout, especially parallel text, and marginals.
The resulting program can be run stand-alone (batch mode) or integrated in the Eclipse plug-in. A Web service will be offered as well.
Figure 3 shows an example of an XML-Print output.


Figure 3: Resulting output of the typesetting engine: Apart from paragraph handling and the use of different fonts the two different types of ‘notes’ (<note type=”footnoteA”> <note type=”footnoteB”>)are both set as footnotes. They are sorted and numbered automatically according to their corresponding format
Further Enhancement
XML-Print has been released as an alpha version and is tested by researchers of different projects, e.g. for a volume of selected letters of Kurt Schwitters (cf. project’s web site, 2011 and figure 3). The typesetting engine as well as the GUI are continuously enhanced, taking into account new user requirements. By extending the attributes for formatting and user-friendly ways, e.g. to generate registers, tables or the type area, XML-Print will offer more and more features to researchers. The development process continues bipartite: On the one hand the support of all standard XSL-FO elements and basic typesetting functionality has to be completed and maybe adapted to a new specification or other output formats, on the other hand advanced algorithms for more complex problems will be developed and implemented.
Within the next months the following tasks will be targeted:
- Continuous work on typographic requirements based on ‘real life examples’
- Integration of the open-source tool xindy for indexes
- Implementation of more output formats, especially PDF variants like PDF-X and PDF-A
- Development of a preview mode to allow faster response to minor changes
With the integration into TextGridLab another large group of new users will get in touch with the software and help to improve it.
References
Brüggemann-Klein, A., R. Klein, and S. Wohlfeil (2003). On the Pagination of Complex Documents. In R. Klein, H. Six and L. Wegner (eds.), Computer Science in Perspective. Berlin and Heidelberg: Springer, pp. 49-68.
Hughes, J. (1990). Why Functional Programming Matters. In D. Turner D. (ed.), Research Topics in Functional Programming. Reading: Addison-Wesley, pp. 17-42. http://www.cs.kent.ac.uk/people/staff/dat/miranda/whyfp90.pdf (accessed 13 March 2012). First published 1989: 10.1093/comjnl/32.2.98
Knuth, D. E. (1986). The TeXbook. Reading: Addison-Wesley.
Knuth, D. E., and M. F. Plass (1981). Breaking paragraphs into lines, Journal Software: Practice and Experience 1111: 1119–1184.
Küster, M. W., and C. Ludwig (2007). Publishing. http://www.textgrid.de/fileadmin/TextGrid/reports/TextGrid-R1_4_Publishing.pdf (accessed 13 March 2012).
Nielsen, J. (1993). Usability Engineering. London: Academic Press.
Ott, W. (1979). A Text Processing System for the Preparation of Critical Editions. Computers and the Humanities 13(1): 29–35.
Warwick, C., M. Terras, P. Huntington, N. Pappa, and I. Galina (2006). The LAIRAH Project. Log Analysis of Digital Resources in the Arts and Humanities. http://www.ucl.ac.uk/infostudies/claire-warwick/publications/LAIRAHreport.pdf (accessed 13 March 2012).
Wie Kritik zur Kunst wird. Project web site, http://www.avl.uni-wuppertal.de/forschung/projekte/wie-kritik-zu-kunst-wird.html (accessed 13 March 2012).
Notes
1.Version 1.0 of the TextGridLab was released in July 2011.
2.There are many attributes intended for XSL-FO 2.0 (e.g. fo:marginalia) and other structures not even specified there. We had to add attributes, e.g. for the placement of footnote apparatus. See the requirements and the latest version of the XSL-FO working draft for more examples.
3.Lisp was the first functional-flavored language in the late 1950s. Modern examples apart from F# are Scala, Haskell and XSLT.