
Introduction
Within the framework of computer vision, the field of image segmentation is becoming increasingly important for a set of applications aiming to an understanding of the visual content, like object recognition and content-based image retrieval. The goal of the segmentation process is to identify contiguous regions of interest in a digitized image and to assign labels to the pixels corresponding to each identified area. While most of today’s searching capabilities are based on metadata (keywords and caption) attached to the image as a whole, one can observe a tendency towards more meaning-oriented approaches intending to split the analyzed image into semantically annotated objects.
From this perspective, research efforts have been dedicated, on one hand, to the task of automated image annotation (Barnard et al. 2003; Johnson 2008; Leong & Mihalcea 2009; Leong et al. 2010), and on the other hand, to the construction of semi-automatically annotated datasets used for supervised image processing (MSRC-v2; Russel, Torralba et al. 2008; CBCL StreetScenes; PASCAL VOC 2007; Welinder et al. 2010). The visual data used for automated annotation may consist, for instance, in images extracted from the Web and the surrounding text in the html pages used as a source of candidate labels (Leong and Mihalcea; Leong et al.). The datasets are mainly derived from digital photographs with the goal to allow recognition of objects belonging to a number of classes like person, animal, vehicle, indoor (Pascal VOC), pedestrians, cars, buildings, road (CBCL StreetScenes), birds species (Caltech- UCSD Birds 200) or to categories interactively defined by users in a Web-based annotation environment (LabelMe).
Our proposal is related to the latter group of applications, i.e. the construction of an interactively annotated dataset of art images (to our knowledge a category less represented in the field), taking into account the textual descriptions of the images intended for analysis. The set of images for segmentation will include digitized icons on themes described in the Painter’s Manual by Dionysius of Fourna. The choice was not arbitrary, given the highly canonical nature of the Byzantine and Orthodox iconography, almost unchanged for centuries, and the close relationship between the text and the pictorial content of the associated icon. Another reason concerns the potential for subsequent applications of learning algorithms to the segmentation of new sets of icons depicting the same themes (and therefore relatively similar content), starting from the initial annotated training set. The choice of a largely circulated text like the Painter’s Manual, translated in several languages, may also serve as a basis for multilingual annotation of the dataset.
The Experiment
The project consists in the use of two types of software, one intended to the segmentation of the visual content, the other to the processing of the textual fragments in order to provide the user with candidate labels for the annotation of the segments. The experiment described below makes use of two open source Java packages, GemIdent – a statistical image segmentation system, initially designed to identify cell phenotypes in microscopic images (Holmes et al. 2009), and the Stanford parser, a natural language statistical parser for English, which can be adapted to work with other languages such as German, French, Chinese and Arabic. Figure 1 presents the original image, The Baptism of Christ (Nes 2004: 66), and the corresponding text from the Painter’s Manual book.

Figure 1 a: ‘The Baptism of Christ’. b: The Baptism of Christ (Dionysius of Fourna 1996: 33). Greek variant. Cretan school. Egg tempera on pine. 78.5 x 120 cm (1989) (Nes 2004: 66)
The image processing involved two phases of colour and phenotype (class or category of objects to be distinguished) training and a phase of segmentation (classification) (see Fig. 2). In the phase of colour training (a), the user can define a set of colours, according to their importance in the analyzed image, by selecting sample points on the image for each colour. We defined four colours: Amber, Blue, Brown, and Yellow. The phenotype training (b) implied the choice of representative points for every object in the picture that should be identified by the program in the segmentation phase. From the processed text with the Stanford parser, we used the following nouns as objects labels: angel, bank, Christ, fish, Forerunner, Holy_Spirit, Jordan, ray, and word. For each phenotype, a colour for the corresponding segment was also chosen (b, c). The program required as well the specification of a NON-phenotype, i.e. an area in the image which does not include any of the above defined objects, in our case the black background representing the sky in the picture.

Figure 2: GemIdent. a. Colour training; b. Phenotype training; c. Segmented image
One can observe that the result of the segmentation process (c) is not perfect. There are small regions belonging to a segment but included in another object: for instance, the light blue (Forerunner) and red (Christ) areas inside the angel objects. GemIdent allows error correction and re-segmentation in order to improve the segmentation process. Although more tests are needed, the results obtained so far seem to indicate a performance depending on the colour selection (tests with same theme pictures, using the trained colour set without colour training on the new pictures, showed less satisfactory results), and on the number and position of the sample points for the phenotype training (ranging from 20 points for small objects like word to 150 for larger objects like bank; selection of sample points from border areas adjacent to different objects seem also particularly important).
On the other hand, the experiment supposed the use of the Type dependency Viewer to visualize the grammatical relationships produced by the Stanford parser, according to the typed dependencies model (Marneffe & Manning 2011). Figure 3 presents the parsing results on the Dionysius of Fourna’s text. The directed edges in the graphs show the dependencies between a governor element (or head) and a dependent, both corresponding to words in the sentence. The edge labels express the grammatical relations between the two words. For example, nsubj refers to a nominal subject relation between a verb (standing, surround) and the syntactic subject of a clause (Christ, fish). Similarly, pobj, dobj connect a preposition (in, of, to) with its object – the head of a noun phrase following the preposition (midst, Jordan, head, Christ) – or, respectively, a verb (surround) and its direct object (Christ). Other relations may refer to adverbial, prepositional or relative clause modifiers (advmod, prep, rcmod), determiners (det), coordination (cc), conjunct (conj), undetermined dependency (dep), etc.
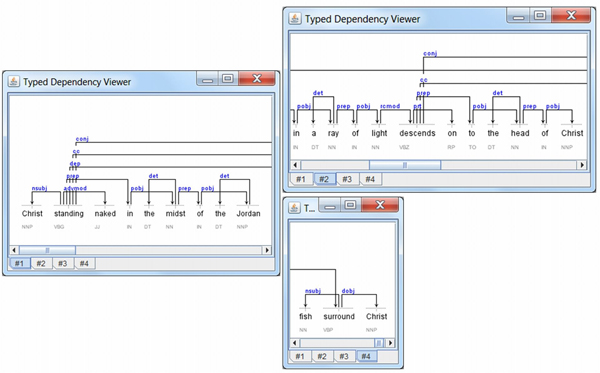
Figure 3: Stanford parser results displayed using the Typed dependency viewer. Excerpts. The Baptism of Christ (Dionysius of Fourna 1996: 33)
A parallel between the pictorial and textual representation of The Baptism of Christ may be further explored. The introductory sentence describing Christ, as a subject of the clause, standing in the midst of the Jordan, is actually pointing to the central figure of the painting. Prepositional or adverbial phrases (such as to the right, to the left, above, below) act as mediators positioning the other elements in the icon relatively to the central figure. Likewise, Christ occurrences in the text as direct or prepositional object (of verbs like rest, descend, look back, surround) are emphasising the ‘focal point’ projection towards which all the other agents’ actions in the pictorial composition seem to converge.
Further development
Since the project is a work in progress, further development will be required:
- more tests, involving new sets of images and associated art-historical description or annotation in another language (if translated variants of the text and an adapted parser for that language are available); tests using similar tools, as the Fiji/ImageJ segmentation plugins, result analysis and comparison with other approaches like, for example, the computer-assisted detection of legal gestures in medieval manuscripts (Schlecht et al. 2011);
- extension of the segmentation process and encoding to include language-based information, i.e. not only objects labels (nouns) but also dependencies reflecting the objects relationships in the textual description (relative positioning, actions agents and objects, by means of verbs, adjectival, adverbial, prepositional modifiers), as they are captured by the pictorial content;
- implementation of a semi-automatic tool combining segmentation and parsing capabilities as in the presented experiment; the tool and images corpus will be available on line so that potential users (students, teachers, researchers in art history or image analysis) can reproduce the results or use them in their own applications.
The DH 2012 presentation will focus on the preliminary stage aspects of the project, e.g. general framework, goals and expectations, experiments and partial results, tools and data choices, model design, more than on an overall quantitative and qualitative results analysis.
References
Barnard, K., et al. (2003). Matching Words with Pictures. Journal of Machine Learning Research 3.
CBCL StreetScenes. http://cbcl.mit.edu/software-datasets/streetscenes (accessed 25 March 2012).
Typed Dependency Viewer. http://tydevi.sourceforge.net/ (accessed 25 March 2012).
MSRC-v2 image database, 23 object classes. Microsoft Research Cambridge. http://research.microsoft.com/en-us/projects/ObjectClassRecognition (accessed 25 March 2012).
Dionysius of Fourna (1996). The Painter’s manual. 1989, 1996, Torrance, CA : Oakwood Publications.
Fiji, http://fiji.sc/wiki/index.php/Fiji (accessed 25 March 2012).
Holmes, S., A. Kapelner, and P. P. Lee (2009). An Interactive Java Statistical Image Segmentation System: GemIdent. Journal of Statistical Software 30(10).
Johnson, M. A. (2008). Semantic Segmentation and Image Search. Ph.D. dissertation, University of Cambridge.
Leong, C. W., and R. Mihalcea (2009). Exploration in Automatic Image Annotation using Textual Features. Proceedings of the Third Linguistic Annotation Workshop, ACL-IJCNLP 2009, Singapore, pp. 56-59.
Leong, C. W., R. Mihalcea, and S. Hassan (2010). The Mining for Automatic Image Tagging. Coding 2010, Poster Volume, Beijing, pp. 647-655.
De Marneffe, M.-C., and C. D. Manning (2011). Stanford typed dependencies manual. http://nlp.stanford.edu/software/dependencies_manual.pdf (accessed 25 March 2012).
Nes, S. (2009). The Mystical Language of Icons. Michigan/Cambridge, UK: Eerdmans Publishing.
The PASCAL VOC. (2007). http://pascallin.ecs.soton.ac.uk/challenges/VOC/voc2007 (accessed 25 March 2012).
The Stanford Parser. http://nlp.stanford.edu/software/lex-parser.shtml (accessed 25 March 2012).
Russell, B. C., A. Torralba, K. P. Murphy, and W. T. Freeman (2008). LabelMe: a database and web-based tool for image annotation. International Journal of Computer Vision 77(1-3): 157-173.
Schlecht J., B. Carqué, and B. Ommer (2011). Detecting Gestures in Medieval Images. IEEE International Conference on Image Processing (ICIP 2011), September 11-14, Brussels, Belgium. http://hci.iwr.uni-heidelberg.de/COMPVIS/research/gestures/ICIP11.pdf (accessed 25 March 2012).
Welinder, P., et al. (2010). Caltech-UCSD Birds 200, California Institute of Technology, CNS-TR-2010-001. http://vision.caltech.edu/visipedia/CUB-200.html (accessed 25 March 2012).