
Iwata, Yoshimi, Doshisha University, Japan, sakunoshippo@gmail.com
Introduction
Noh is a classical Japanese stage art consisting of singing and dancing with musical accompaniment. The song lyrics have been documented and are known as Noh texts. It is generally accepted that there are 240 songs, which are still performed today. However, some academic scholars claim that there are more than 500 Noh texts in existence. The texts take on different forms depending on the Noh school and the era in which they were edited.
Very little analyses have been carried out on Noh texts by applying mathematical methods. Therefore, in previous studies, Noh text was analyzed by identifying the authors of each Noh play using mathematical methods. This study employed mathematical and statistical methods to analyze 21 songs including worrier play category from Noh plays. Specific usage within lexical categories (auxiliary verb, adjective) was identified. As in Noh play, there are manuscripts which differ by the Noh school and the era being edited, the manuscripts under study need to be chosen adequately. Therefore, it is necessary to trace the history of each Noh text using phylogenetic analysis. At the same time, one has to be aware of the differences between engineering and literary approaches.
Purpose of research
The purpose of this research is to establish a new methodology in Noh field by employing mathemathecal and stylometric techniques. First, data is collected from various research materials and a database is constructed that facilitates preliminary analyses to verify items in the collected data or to draw a complete map for further studies. Practical analyses directly connected to interpretations are based on the preliminary analyses. Although, in Japan, these processes are common in both engineering and literary approaches, attitudes to analyses are completely different. In engineering approaches, final conclusions are derived from practical analyses. In contrast, in literary approaches, analyses and interpretations are essentially synonymous and interpretive understanding is given more importance than scientifically based analyses. Therefore the discussions with other fields, such as information science, are required in each research process. Additionally, linguistic and cultural barriers make foreign researchers to spend a lot of time and care on understanding the research materials. Standing on this point, versatile methodology not to depend on researchers’ skills of language is required. Normalized Compression Distance (NCD) method, the author focused on in this paper, calculates similarity of texts objects by using compression algorithm without any knowledge about the research materials.
Previous Researches
Two previous research applied biological methodologies to cultural phenomena.
A. Split decomposition, Spectronet
Tamaki Yano (2005)
Tamaki Yano applied Phylogenetic methods to collections of traditional Japanese ‘waka’ poems edited in 1215 [1]. The term ‘waka’ is a form of poem handed down from ancient times in Japan. The research materials had some versions that departed from the original, and the research aimed to identify an archetype for the differing collections. In this study, the genealogy of each collection is visualized by neighbor-net, a distance-based method for constructing phylogenetic networks that is based on the neighbor-joining algorithm of Saitou and Nei [2].
B. Database and Semantic Analysis for Fine Arts Based on Researchers’ Experience –The Case of ‘A Hundred Beauties’ Drawn by YAMAGUCHI SOKEN
Yuka Iemura, Yu Fujimoto (2010)
In Iemura and Fujimoto’s research, NCD was used to calculate the similarity distance because of its simplicity. Suppose, for instance, there are two files named ‘x’ and ‘y,’ C(xy) is the compressed size for the concatenation of files ‘x’ and ‘y.’ C(x) denotes the compressed size of ‘x’ and C(y) denotes that of ‘y.’ Fujimoto and Iemura attempted to apply this method to XML documents and the results were visualized using neighbor-net. They concluded that the results properly reflected differences between each XML document [3].
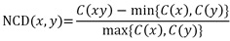
Analysis
This study examined Tadanori (忠度), one of the 240 existing songs. Tadanori is one of the oldest accessible manuscripts, and anyone can browse the full version of the photocopied manuscript. In addition, this masterpiece is popular even now, and thus, there is a considerable relevant material that makes it possible to trace the history of the Noh texts (Table 1). Eleven different Tadanori manuscripts were transcribed as data files. The size column in Table 1 shows the byte size of the manuscripts.

A. NCD
To create text files for NCD, all kanjis were converted to Japanese hiragana using Visual Basic for Applications (VBA).
NCD was calculated by Hyakka-One, which is a NCD calculating software developed by Fujimoto. The software currently supports zip, gzip, and bzip algorithms. General zip compression was used in this study. Although the original advocates of NCD recommend the quartet method for clustering, neighbor-net was used to visualize the genealogy of Noh-hon. The distance matrix calculated by Hyakka-One was exported to phylogenetic tree software, Splits Tree4, and visualized as a phylogenetic network called a neighbor-net. The neighbor-net derived from the NCD matrix is presented in Figure1.
B. Phylogenetic approach
The phylogenetic approach involves two methods. The first is a method for detecting differences between each group of phrases and calculating distances for a phylogenetic tree. The second, which is used to verify the results of the NCDs, is based on the maximum parsimony method. PAUP*4.0 software was used for this verification in this study. PAUP* is commonly used in cladistics or phylogenetics. To apply the second method, data cleaning is required to conflate each Noh text and extract the different phrases, make groups of phrases, and replace the groups with single letters. The process of separating Noh texts into phrases is not required by the NCD method. The methods provide different results based on differences between phrases. PAUP* returned 841 results. Although the lengths of edges are shorter than the NCD results, they are similar. These result were integrated using super-network and the integrated results were displayed using Splits Tree4.
Results
Three results were obtained by the distance method by SplitsTree4 (Figure 2), the Super-Network by the maximum parsimony trees (Figure 3), and the distance method by NCD (Figure 1). In all three results, the kp and kz groups are apparently separated. This means the texts can be categorized according to schools. With regard to hs_1979, all three networks show that hs_1979 is closer to the kz group. Related to the forms of performance, it is generally accepted in the Noh community that the hs group and the kz group are part of the same group, while kp belongs to other groups that were not included in this study. Therefore, these three results support the generally accepted ideas. Although NCD tends to be criticized because of the difficulty involved in verifying the results, in this study, the NCD approach gives enough results on grouping and can be applied to preliminary analysis. The advantage of NCD is the simplicity of its data cleaning process. Because of this simplicity, foreign researchers who are not fully familiar with the Japanese language or researchers of literature and have a limited knowledge of engineering can handle the data. The other two methods require familiarity with both Japanese and engineering. NCD has a disadvantage for the practical analysis stage. Because NCD depends on a complex compression algorithm, it is difficult to perform verification using the original texts.
Conclusion
The NCD approach has been successfully applied to Noh research. In this initial study, the results from the NCD method were not significantly different from the other two common methods, and it is reasonable to conclude that the NCD method can support traditional Noh studies equally as well as the other two methods. In future research, the author will attempt to apply NCD to other Noh plays and determine if it is valid to use the method for preliminary analysis. It is acknowledged that it will be necessary to develop database schemas that can potentially generate text plans for calculating NCD.

Figure 1: Neighbor-net for texts of Tadanori derived from NCD distance

Figure 2: Neighbor-net for texts of Tadanori derived from standard distance method

Figure 3: Super-network for texts of Tadanori derived from the maximum parsimony method (PAUP*)
References
Yano, T. (2005). Split decomposition, Spectronet. Japan. The Special Interest Group Notes of IPSJ SIG Computers and the Humanities, pp. 33-40.
Saitou, N., and M. Nei (1987). The neighbor-joining method: a new method for reconstructing phylogenetic trees. Molecular Biology and Evolution 4: 406-425.
Iemura, Y., and Y. Fujimoto (2010). Database and Semantic Analysis for Fine Arts Based on Researchers’ Experience – The Case of ‘A Hundred Beauties’ Drawn by YAMAGUCHI SOKEN. Proceedings of Third Japan Art Documentation Society, pp. 12-15.
Omote, A. (1965). The Study of Kozanbunkobon – the part of Utaibon –. Tokyo: Wanya Bookstore.
Yokomichi, M., and A. Omote (1960). Youkyokusyu 1 & 2 (Tokyo: Iwanami Bookstore).