
van Zundert, Joris Job, Huygens Institute for the History of the Netherlands – Royal Dutch Academy of Arts and Sciences, The Netherlands, joris.van.zundert@huygens.knaw.nl van Dalen-Oskam, Karina, Huygens Institute for the History of the Netherlands – Royal Dutch Academy of Arts and Sciences, The Netherlands, karina.van.dalen@huygens.knaw.nl
This paper reports on our ongoing stylistiscs research and tool development in the specific case of authorship attribution for the Middle Dutch Arthurian novel Roman van Walewein (Romance of Gawain). First we introduce the use case, and we concisely recapture our prior research. We then progress to the description of the re-issued improved software and algorithm we developed and applied to our use case. We conclude with an overview of the first results we derived from applying our tools and approach.
The Roman van Walewein (ca. 1260, Middle Dutch) was written by two authors, Penninc and Vostaert. Only one manuscript containing the complete text, explicitly dated as copied in the year 1350, is left to us. Some fragments of another, probably somewhat younger manuscript contain about 400 lines. The text in the complete manuscript consists of 11,202 lines of rhyming verse. The manuscript was written by two copyists. The first seems to have written the lines 1-5.781 and the second the lines 5,782-11,202.
The second author, Vostaert, explicitly claims to have added about 3,300 lines to Penninc’s text. Several scholars of Middle Dutch have pointed out on various grounds that Vostaert (or the copied text) can not be correct in this claim. We decided to apply current state of the art authorship attribution techniques to find whether this would point us to a specific line in the text where the text before that line and the text after that line contrast the most. In prior research we have used a lexical richness measure, Udney Yule’s Characteristic K, and Burrows’s Delta to try to determine the position in the text where Vostaert may have started to complete Penninc’s text. We thus found that applying Burrow’s Delta indeed gives relatively strong grounds to assume that Vostaert simply stated a truth. Figure 1 can be read as a support of this finding, showing a significant change of stylistic stability occurring around verse line 7,882 (cf. van Dalen-Oskam & van Zundert 2007). New knowledge that we derive from this result is that Vostaert may well have reworked the last portion of his predecessor’s work. However, the most surprising result was that our analysis pointed towards the possibility that Delta is a better indicator for a change of copyists than anything else (cf. the clear local maximum in the graph of figure 1, which is located around verse line 5,783 and reflects the change of hands that takes place in the manuscript).
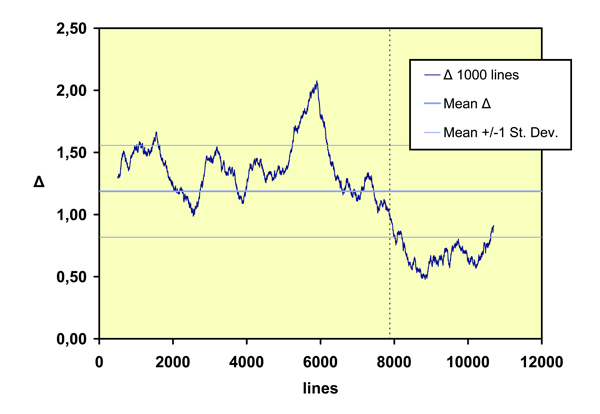
Figure 1: ‘Walking’ Delta. The text corresponding to lines 8,000 – 11,000 in Vostaert’s part of the romance was used as a subset for the procedure. From this subset the top most 50 frequently used words were used for comparison with the text in a ‘sliding window’ of each consecutive 1,000 lines. Taken from (van Dalen-Oskam & van Zundert 2007)
In our research until 2007 we were only able to tentatively look into this copyist distinguishing ability of the Delta measure, and it remains to be investigated until now how effective Delta is as a procedure for copyist distinction. Although Kestemont and van Dalen-Oskam (Kestemont & van Dalen-Oskam 2009) verified the difference between the two scribes of the extent Walewein manuscript using a lazy machine learning technique on other features such as character n-grams and several simple rations, they did not apply a form of Delta procedure to this problem. In our 2007 article we stated that the current application cannot easily and automatically generate and compare a large collection of Delta graphs based on an iterative subselection of a word frequency list’ (van Dalen-Oskam & van Zundert 2007: 360). This is the point where we resume our research endeavor.
We have further developed our ‘sliding window’ approach to measuring the stylistic consistency of texts (i.e. the ability to establish the stability of the value of Delta throughout a single text). We will release the MIT licensed open source Ruby code for this version of the software to Github in June 2012. This version will include a REST-full interface to accommodate polling this tool as a web enabled programmatically negotiable service, a web GUI for human-computer based interaction with the tool, and user documentation as well as format description specifics required for files to be parsed with this tool.
Our analyses until 2007 relied on stepping a ‘window’ through a text, computing the Delta for that window of text using the complete text as a statistical background and a sizeable portion of the part unanimously attributed to Vostaert as a Delta comparison base. The graphs thus computed showed the consistency (or non consistency) of Delta throughout the text tested. Having improved scalability and performance of the algorithm we are now able to run several Delta measuring windows through a text at higher speeds, enabling near instant analysis (typically <5s analysis time for a 65k tokens sized text, analyzed through an approximately 8k token sized window).
This improved approach has enabled us to return to the research question at hand: how well does Delta discriminate copyists? With the current software we are able to determine how stable the characteristic is for Delta that we found in our first computations (see Fig. 1.) throughout the word frequency spectrum of the text. Our algorithm computes the Delta characteristic of a text in an iterative subselection of the word frequency list. For instance, it computes this characteristic first in the top 50 highest frequency spectrum, then it does the same for the top 10 to 60 highest frequencies, then for the top 20 to 70 highest frequencies, then 30–80, 40–90, etc… The size and ‘pace’ of the frequency subset window can in fact be chosen arbitrarily, though sensible heuristics need to be applied to yield meaningful results. In essence then, the current algorithm not only slides a window for Delta measurement through the text, but also slides a measurement window through the frequency spectrum of the vocabulary of the text. In the case of Walewein this yields typically a result as depicted in Fig. 2.
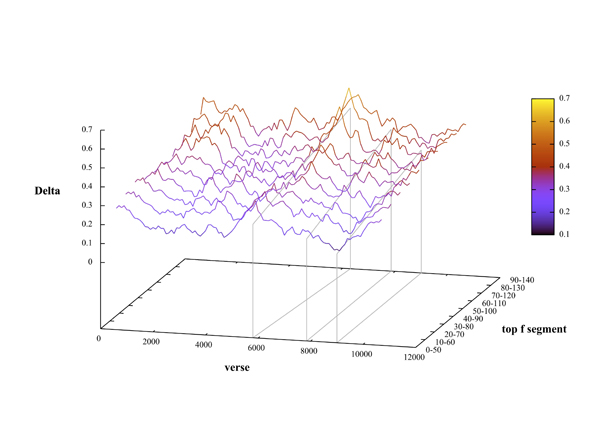
Figure 2: Sliding the ‘walking’ Delta through a consecutive subset of the full vocabulary frequency spectrum of the text of Walewein
There are several conclusions we can draw from this result. The general characteristic we found in our earlier attempts to establish the stylistic consistency throughout the text of Walewein holds for any subspectrum of high frequency vocabulary we choose. We conclude that the reproduceability of this characteristic in different frequency spectra, means that indeed this is a viable method of tracing stylistic consistency in a text. We also note that the value for Delta on average rises slightly when our window on the subset of high frequency word usage descends through the full spectrum of vocabulary frequencies. This in itself confirms that Delta is a valid indicator for stylistic similarity, or at least for similarity in high frequency word usage. But more important: because the peak of stylistic inconsistency around verse 5,782 is stable our findings also confirm our tentative assumption that ‘semi-high’ frequency word usage is a better indicator for copyist change than high frequency word use – at least in the specific case of the Walewein. We can in the case of Walewein also infer which part of the high frequency word use spectrum is the best indicator of copyist change: the 80 to 130 most frequently used words. Discussing the lexical characteristics of this part of the vocabulary as well as what this may indicate about copyist behavior will be part of our paper.
Further testing on known use cases of copyist change need to establish whether this result is generalizable. If so, we may have found in this particular application of the Delta procedure an adequate identification procedure for copyist change.
References
Burrows, J. F. (2007). All the Way Through: Testing for Authorship in Different Frequency Strata. Literary and Linguistic Computing 22: 27-48.
Burrows, J. F. (2002). ‘Delta’: a Measure of Stylistic Difference and a Guide to Likely Authorship. Literary and Linguistic Computing 17: 267-287.
Hoover, D. (2004). Testing Burrows’s Delta. Literary and Linguistic Computing 19: 453-475.
Van Dalen-Oskam, K. H., and J. J.van Zundert (2007). Delta for Middle Dutch: Author and copyist distinction in “Walewein”. Literary and Linguistic Computing 22: 345-362 (First published June 2, 2007: 10.1093/llc/fqm012).
Kestemont, M., and K. H. van Dalen-Oskam (2009). Predicting the Past: Memory-Based Copyist and Author Discrimination in Medieval Epics. Proceedings of the twenty-first Benelux conference on artificial Intelligence (BNAIC, 2009), Eindhoven, The Netherlands, pp. 121-128.
Smith, P. W. H., and W. Aldridge (2011). Improving Authorship Attribution: Optimizing Burrows’ Delta Method. Journal of Quantitative Linguistics 18: 63-88 (First published February 24, 2011: 10.1080/09296174.2011.533591).
Stein, S., and S. Argamon (2006). A Mathematical Explanation of Burrows’s Delta. Proceedings of Digital Humanities 2006, Paris, France, July 2006, p. 207 <http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.71.8771&rep=rep1&type=pdf> (accessed 14 March 2012).
Johnson, D. F., and G. H. M. Claassens (2000). Dutch Romances I: Roman van Walewein. Cambridge: D.S. Brewer.